Pieces Copilot
Describe and chat about your code with Pieces Copilot. You can ask a technical question and Pieces' ML models will generate functional code to use in your projects.
Getting Started With Pieces Copilot
Navigate to the Copilot & Global Search view from the dropdown, and you will see the Copilot chat box towards the middle of the app window. If you're looking for more information about Global Search, you can find details here.
You can start chatting with the Pieces Copilot using a few different actions:
- Paste code into the chat box, and the Copilot will let you know if there are any issues.
- Try pasting this code snippet:
function build(){
console.log("build starting");
let _count;
for (let i = 0; i <= 10; i++){
_count = _count + 1;
console.log($_count);
}
console.log('counted to ten!');
}- The Pieces Copilot will identify, explain, and correct a couple of errors.
- Try pasting this code snippet:
- Ask a technical question, and the Copilot will answer.
- Here are a few examples to try:
How do I create a flexible div with 8px of padding on both sides?Loop over a directory of files and write the first line of their contents to a new text file.
- Here are a few examples to try:
- Drag and Drop a screenshot of code, and the Pieces Copilot will extract the code, explain it, and answer questions about it.
- Pressing
Scan Screenshotallows you to select a screenshot using your native file picker. - Read about dragging and dropping code into the Pieces Desktop App on the Saving Screenshots Page.
- Pressing
Results from Pieces Copilot
When the Pieces Copilot returns code, you will see a few quick actions at the bottom of the code block. These actions include:
| Action | What it Does |
|---|---|
| Save to Pieces | Saves the snippet to your Pieces repo, so it's available across plugins and extensions. |
| Share | Saves the snippet and generates a shareable link to send to another user. |
| Annotate Code | Adds comments to the code to describe sections, functions, and variables. |
| Find Similar Code Snippets | Searches your existing code snippets for code that is similar to the generated snippet. |
| Tell Me More | Describes the snippet to you in plain text and tells you what the code does. |
| Repair & Tidy | Improves the code by removing repetition, loops, or other bad practices. |
| Show Related Links | Shows a list of related links to that code snippet and its topic. |
| Show Related Tags | Shows tags that are relevant to the snippet. |
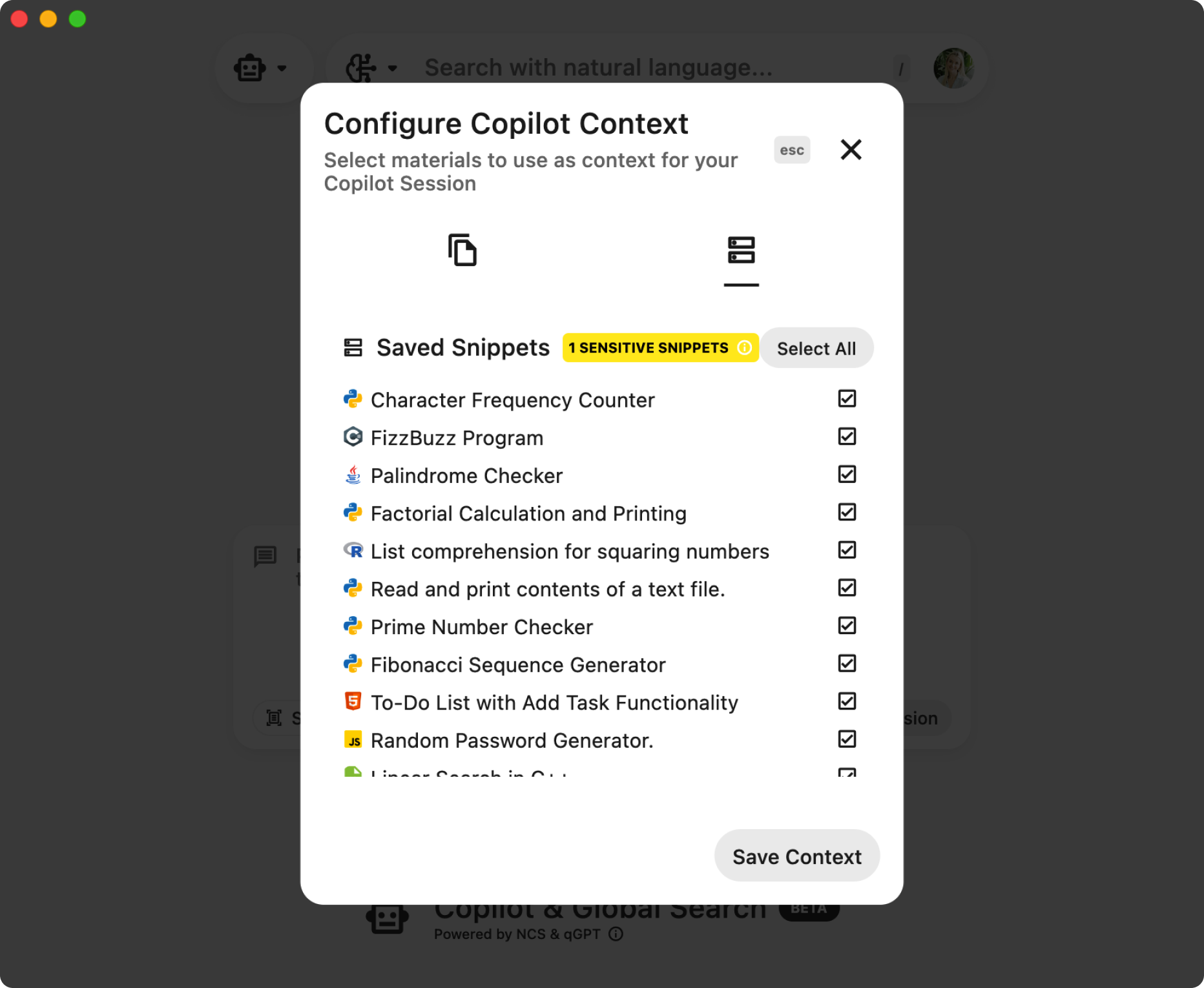
Set Your Own Copilot Context
File Context
File context is crucial for enhancing the assistance provided by Pieces Copilot, allowing it to better understand the specific coding environment of the file you are currently working on.
By integrating the Copilot with your IDE, such as VS Code or JetBrains, and activating it, the system automatically detects and adapts to the file you have open. This automatic detection improves the relevance of the Copilot’s suggestions, streamlining your workflow and reducing the need for manual descriptions of your codebase.
Project Context
Project context enables the Copilot to consider all aspects of your project, including files, dependencies, and overall architecture. By enabling the Copilot at the project level within your IDE, it gains the ability to index and understand the entire project structure, which enhances its capability to offer comprehensive and relevant coding solutions and suggestions.
Holistic Assistance
With a full understanding of the project’s scope, the Copilot can provide solutions that take into account the interactions between various components and dependencies. This not only helps in maintaining consistency across files but also assists in identifying potential improvements or conflicts within the project.
Code Snippets
Providing code snippets directly to the Copilot sharpens its focus and enhances the specificity of the assistance offered. This can be done by using context menu options in your plugin to add specific code snippets to the Copilot.
These snippets help the Copilot understand the precise syntax and functionality you are dealing with, allowing it to offer targeted solutions and suggestions.
Live Context
Live Context comes from the Workstream Pattern Engine and enables the copilot to capture real-time context from any application on your desktop, making it aware of your recent activities and work-in-progress journey. This dynamic understanding allows the copilot to provide hyper-personalized responses and suggestions based on your recent workflow.
By enabling the Workstream Pattern Engine in the Pieces settings, the copilot can reference your recent activities, discussions, and code changes, tailoring its responses and interactions to your unique project.
Temporal and Conversational Awareness
Live Context allows for a more intuitive and seamless interaction with the copilot, as it can recall and reference recent work contexts and discussions on a time-basis. Whether you're asking about a recent error, a discussion point with a colleague, or to summarize your workflow yesterday, the copilot uses its temporally grounded knowledge to provide relevant and timely assistance.
Website Context
Website Context allows the Copilot to understand the content of websites. By using the Pieces Web Extension to add a website to your Copilot context, the system automatically extracts relevant content and integrates this information into the Copilot’s knowledge base.
This capability is particularly beneficial when you are researching or capturing information as part of your development process.
Message Context
Adding copilot messages to context means that the Copilot puts more importance on those messages than others when using context to generate a response.
This feature is instrumental in ensuring that the Copilot’s assistance is aligned with your current priorities.
Snippet Specific Copilot
When viewing a snippet in Gallery or List View, you can launch copilot on a snippet that you have saved to Pieces for Developers. To do this, use the Quick Action labeled Launch Copilot above the snippet in List View.
Note that if you are in Gallery View, the action buttons are below the code snippet.
Launching Pieces Copilot on a specific snippet - instead of using it in the Global Search view - allows the bot to already have context and additional information about the snippet you want to ask specific questions about. Leveraging the question and answer system, you can ask questions such as:
What does this snippet do?
or
How can I make this snippet better?
You can keep this very high-level and ask simple questions related to the code snippet as a whole, and you can ask questions about parts of the code.
For example, using the JavaScript code snippet above, you could ask:
What is the purpose of the "build" function in this code snippet?How does the loop in the build function work?What does the variable "_count" represent in this code snippet?How many times will the loop iterate in the build function?What will be logged to the console when the "build" function finishes counting?
When you "Launch Copilot" on a snippet, you will get a list of suggested questions to help get you started. You can click any of the options that are put in your chat to start the conversation, then add more questions on top after the bot responds.
Continuing the Copilot Conversation
If you are in the midst of a conversation with Pieces Copilot and need to navigate to a different view, reference a separate snippet, or move to another location, don't worry. Conversations with Copilot are saved with the snippet that you had the individual conversation about so that you can get back to where you were when jumping around. You'll notice that once you start a conversation, the Launch Copilot Quick Action pill will change to Resume Copilot.
Available Copilot Runtimes
Our Copilot also comes with multiple different LLM runtimes, cloud and local in order fulfill whatever requirements your workflow entails.
Cloud Runtimes
OpenAI
- GPT 3.5 Turbo, a highly optimized LLM created by OpenAI designed for quick and accurate responses.
- GPT 3.5 Turbo 16k, a highly optimized LLM utilizing a larger set of parameters for more accurate responses.
- GPT 4, containing even more context than the previous models, capable of completing more complex tasks than its predecessors.
- GPT 4 Turbo, a highly optimized LLM created by OpenAI designed for quick and accurate responses.
- GPT 4o, OpenAI's new flagship model that can reason across audio, vision, and text in real time.
Gemini
- Gemini Pro, Google's most capable AI model, built to be multimodal and able to complete a wide variety of tasks.
PaLM 2
- Chat Bison, a Developer model optimized around key use cases for understanding multi term conversations
- Code Chat Bison, a model fine-tuned to generate code based on a natural language description
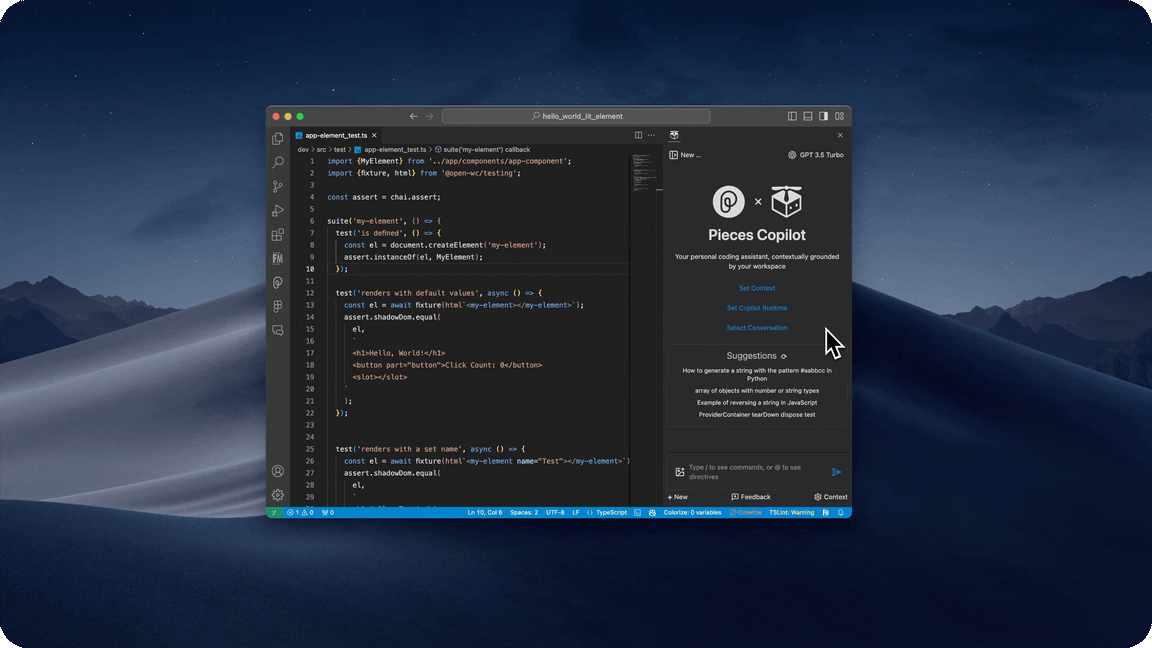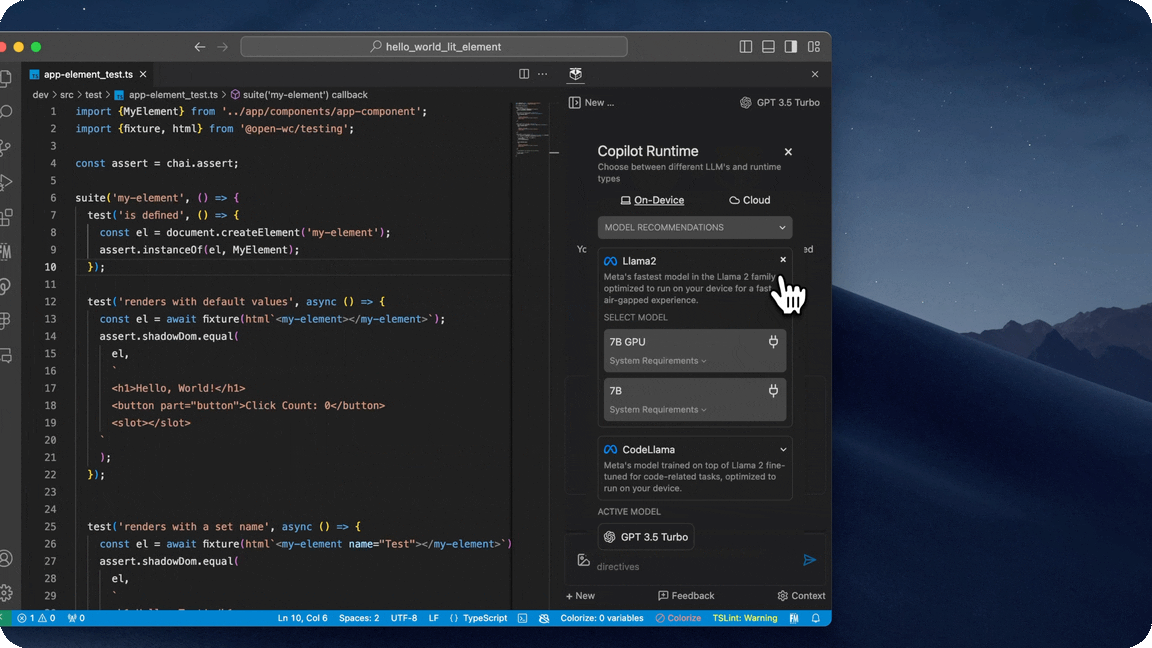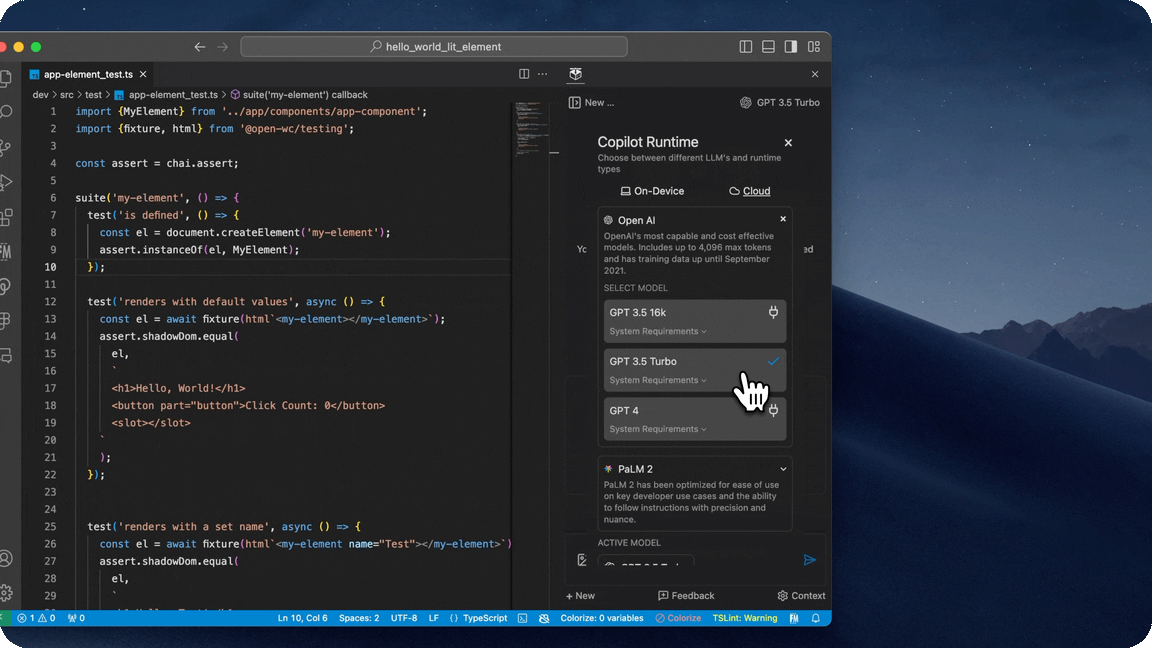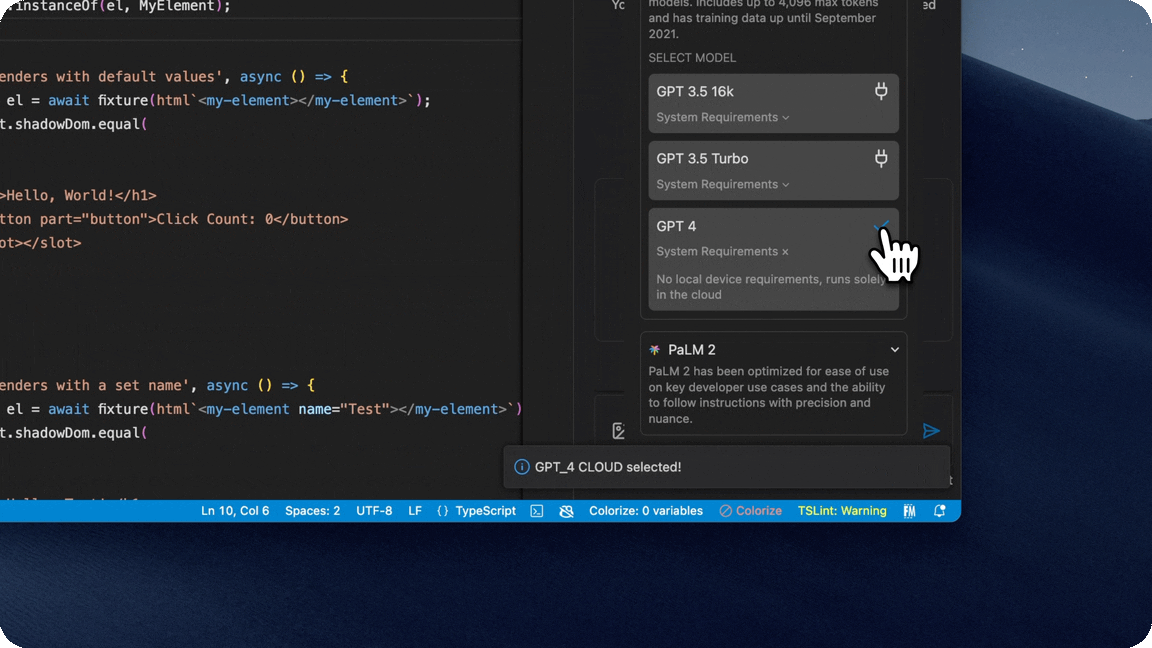
Local Runtimes
Disclaimer: Running Large Language Models locally on-device is typically resource intensive. As of right now, a majority of our Local LLMs leverage roughly 7 billion parameters. To ensure optimal performance, we recommend the following minimum specifications:
- CPU: A modern, multi-core processor with at least 4 cores.
- RAM: At least 8GB of system memory.
- GPU (Optional): A dedicated GPU with at least 4 GB of VRAM is recommended for optimal performance.
- NVIDIA: GeForce RTX 2000 series or newer.
- AMD: Radeon RX 5000 series or newer.
- System Age: A machine from 2021 or newer.
- Llama2 7B, a model trained by Meta AI optimized for completing general tasks, also available in a CPU and GPU runtime.
- Requires a minimum of 5.6GB RAM for the CPU model and 5.6GB of VRAM for the GPU-accelerated model.
- Mistral 7B, a dense Transformer, fast-deployed and fine-tuned on code datasets. Small, yet powerful for a variety of use cases. Outperforms Llama 2 13B and 34B on most benchmarks.
- Requires a minimum of 6GB RAM for the CPU model and 6GB of VRAM for the GPU-accelerated model.
- Phi-2 2.7B, a small language model that demonstrates outstanding reasoning and language understanding capabilities.
- Requires a minimum of 3.1GB RAM for the CPU model and 3.1GB of VRAM for the GPU-accelerated model.
Plugin Integrations
Our VS Code, Jetbrains, Visual Studio, Web Extension, Obsidian, and JupyterLab integrations all offer the same copilot chat features, ensuring a consistently powerful experience wherever you need it.
Features
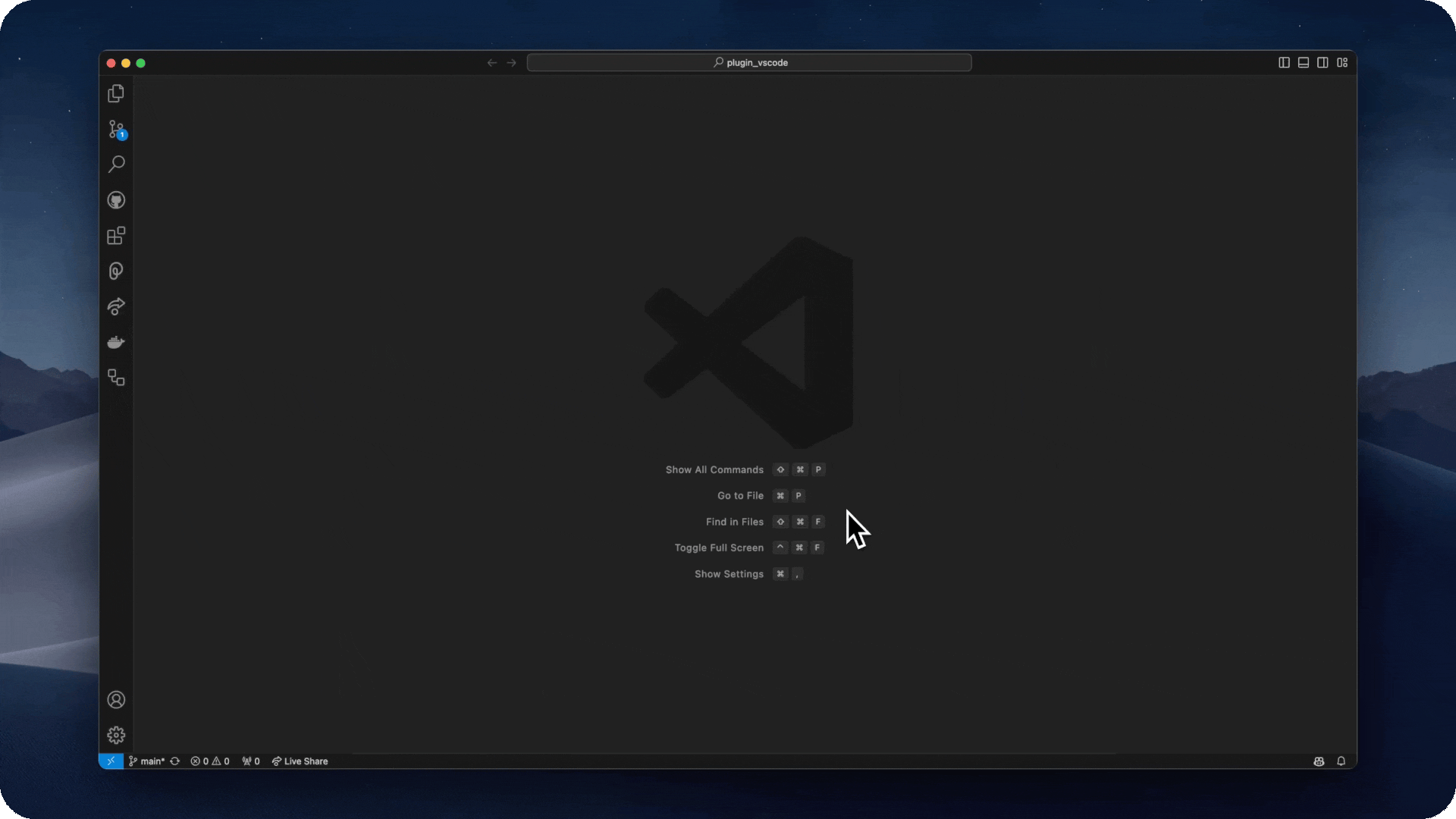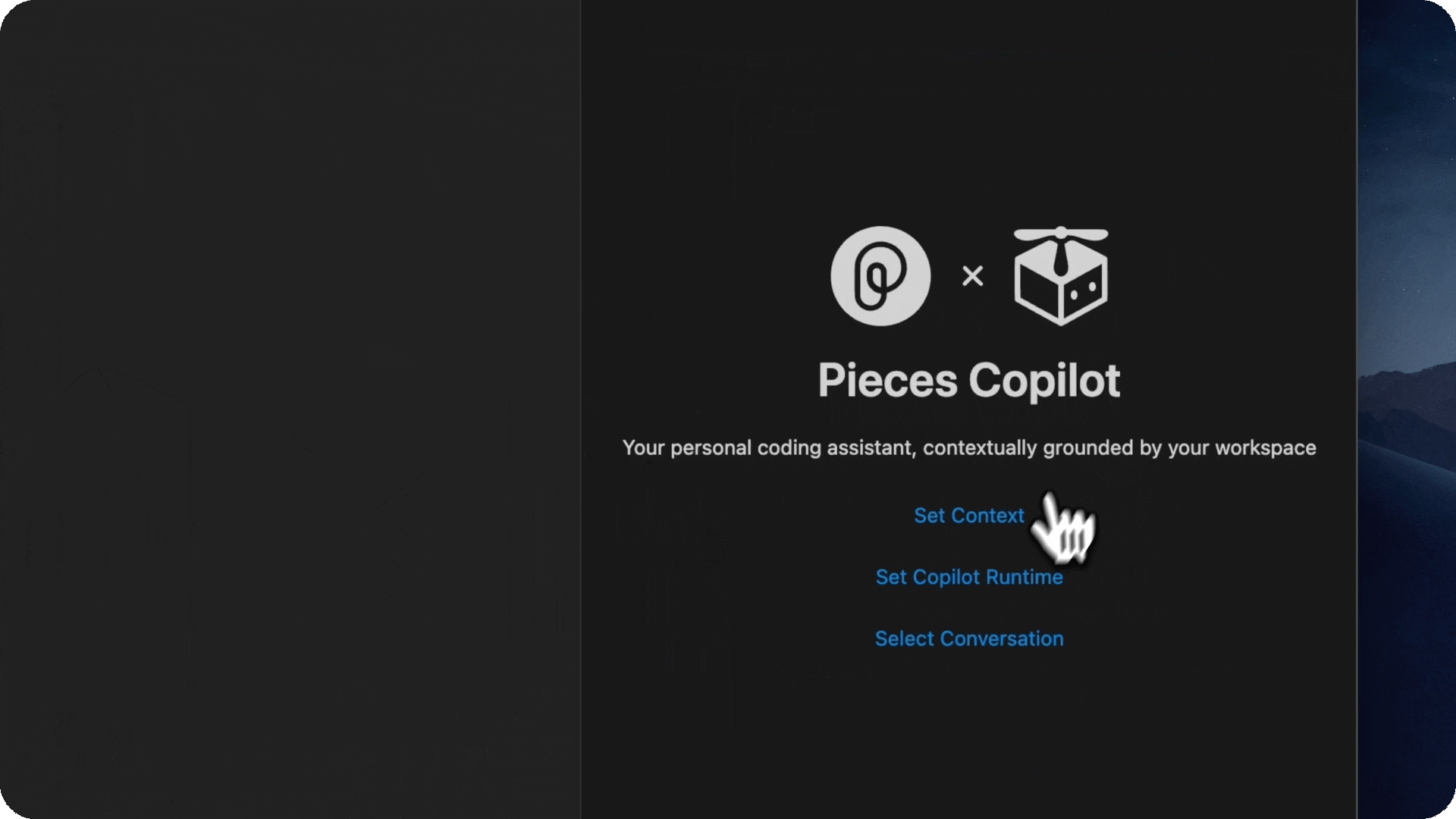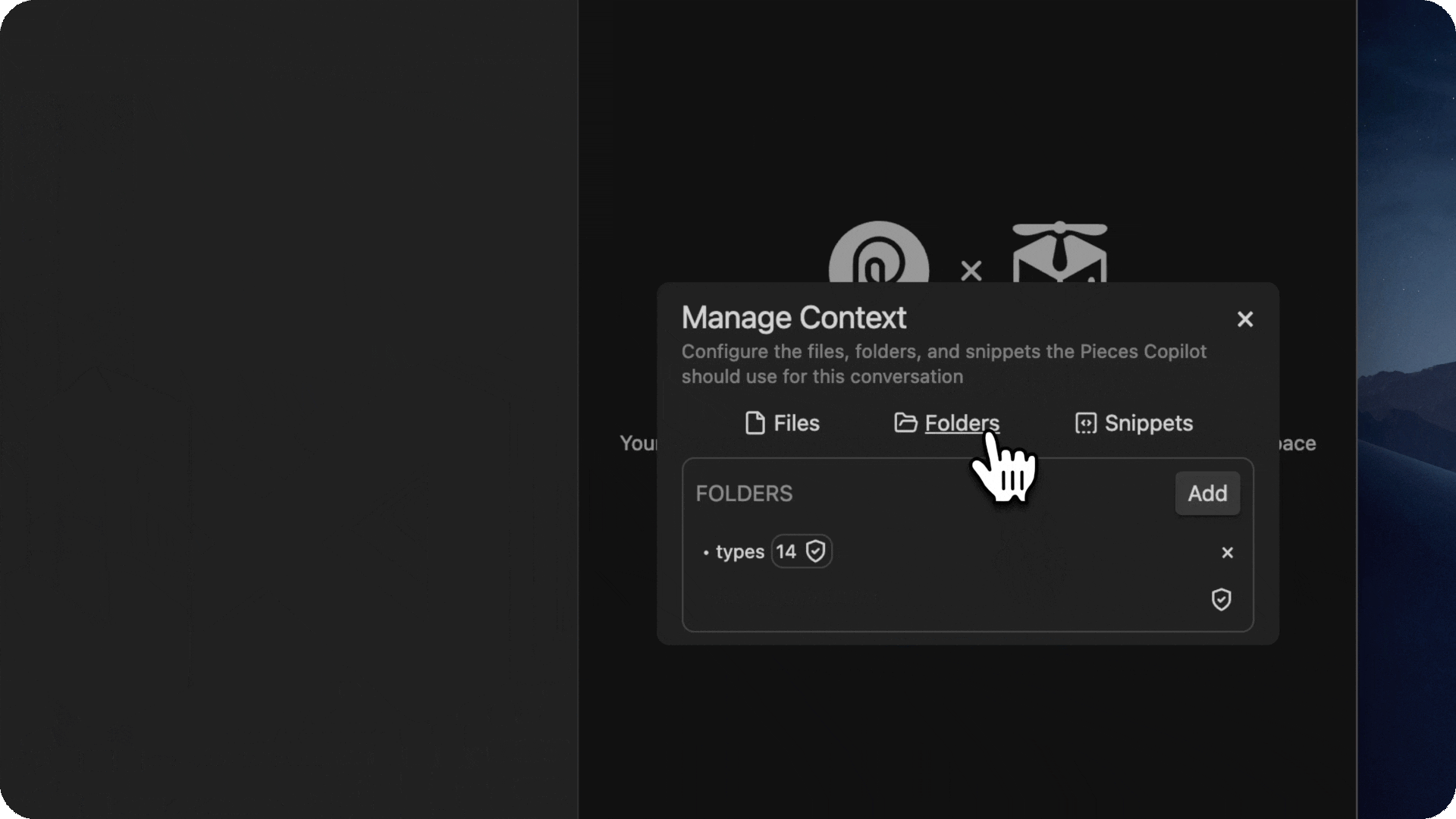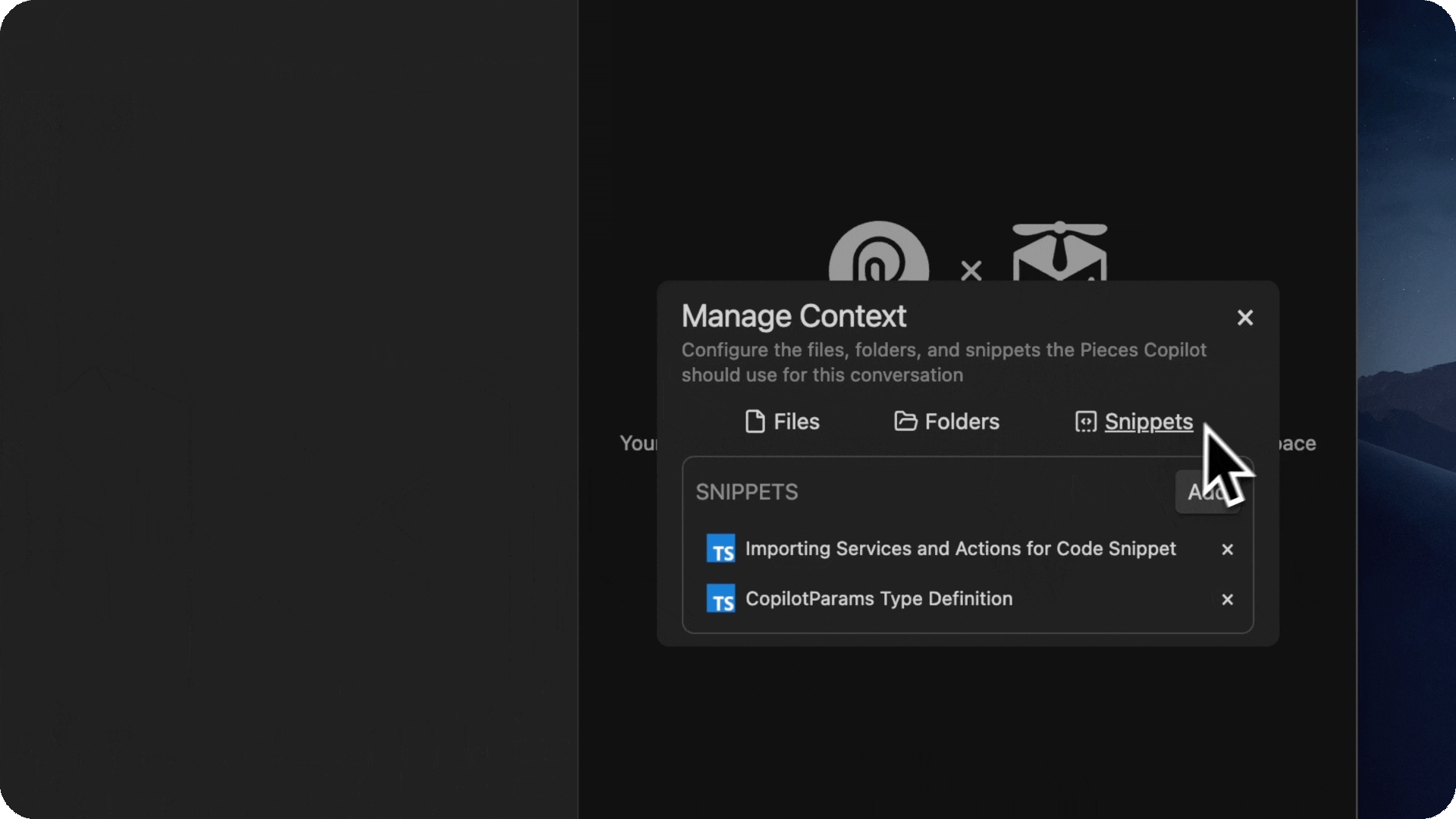
- Chat with any of your materials, anywhere
- You can use files, folders, and snippets as context in order to ask the copilot about them.
- You can use files, folders, and snippets as context in order to ask the copilot about them.
- Select multiple different LLM runtimes, including local LLMs for offline, airgapped security
- We have an extensive list of LLMs to choose from depending on your use case including GPT-3.5, GPT-3.5 16k, GPT-4, PaLM 2 and Gemini, as well as local LLMs such as Llama2 and Mistral (CodeLlama and TinyLlama coming soon).
- We have an extensive list of LLMs to choose from depending on your use case including GPT-3.5, GPT-3.5 16k, GPT-4, PaLM 2 and Gemini, as well as local LLMs such as Llama2 and Mistral (CodeLlama and TinyLlama coming soon).
- Extract code from images
- Extract code from a screenshot either by pasting it into the copilot input, or by clicking on the image icon in the input box.
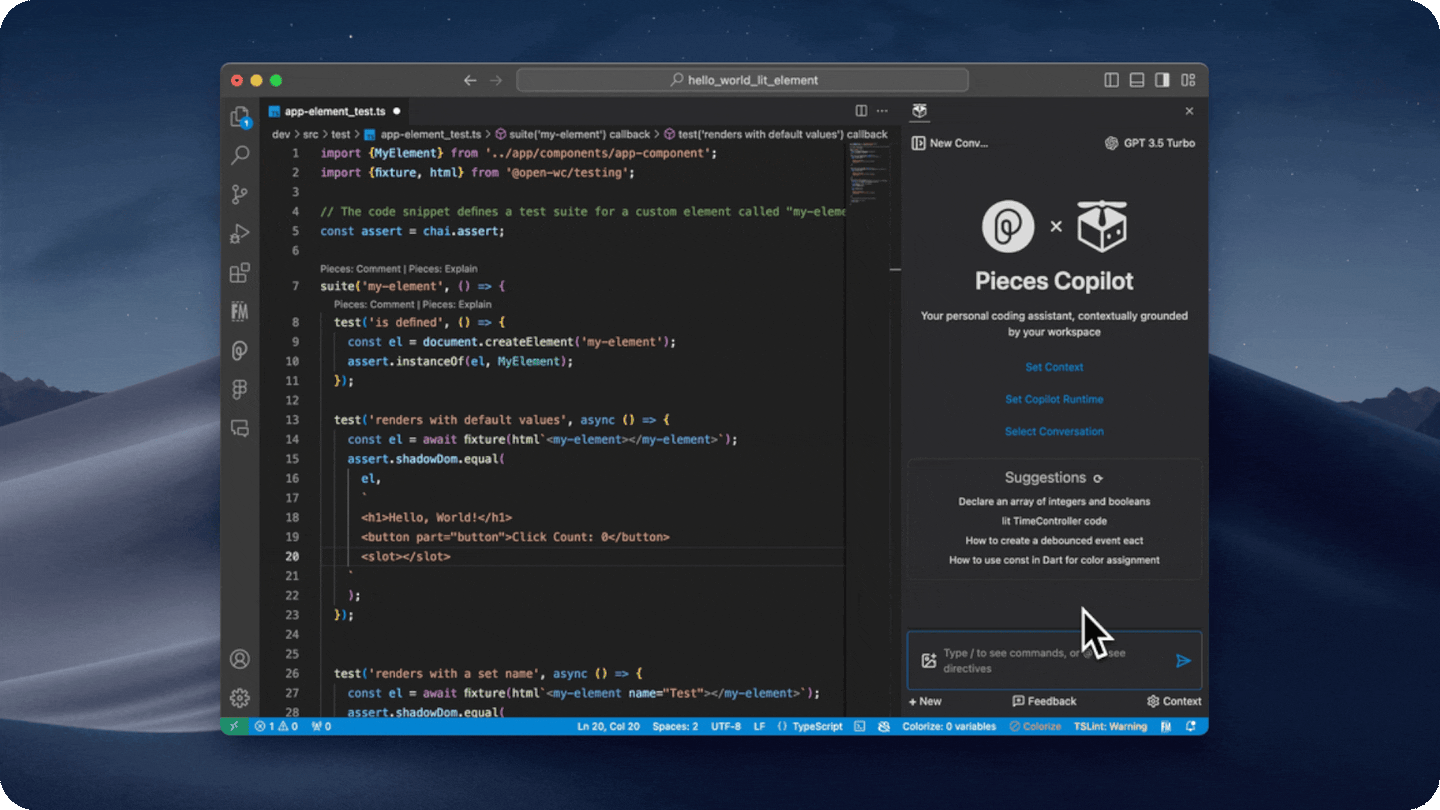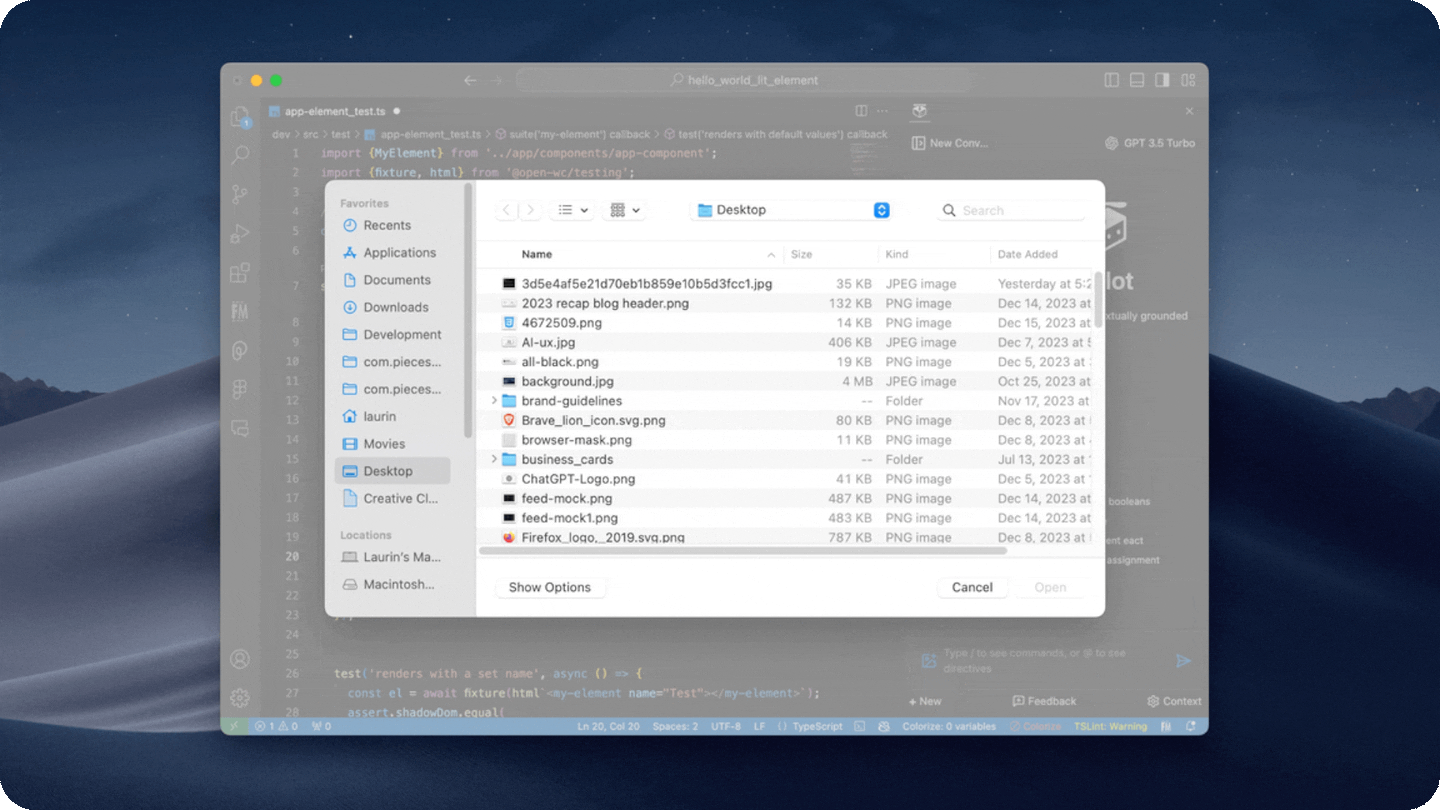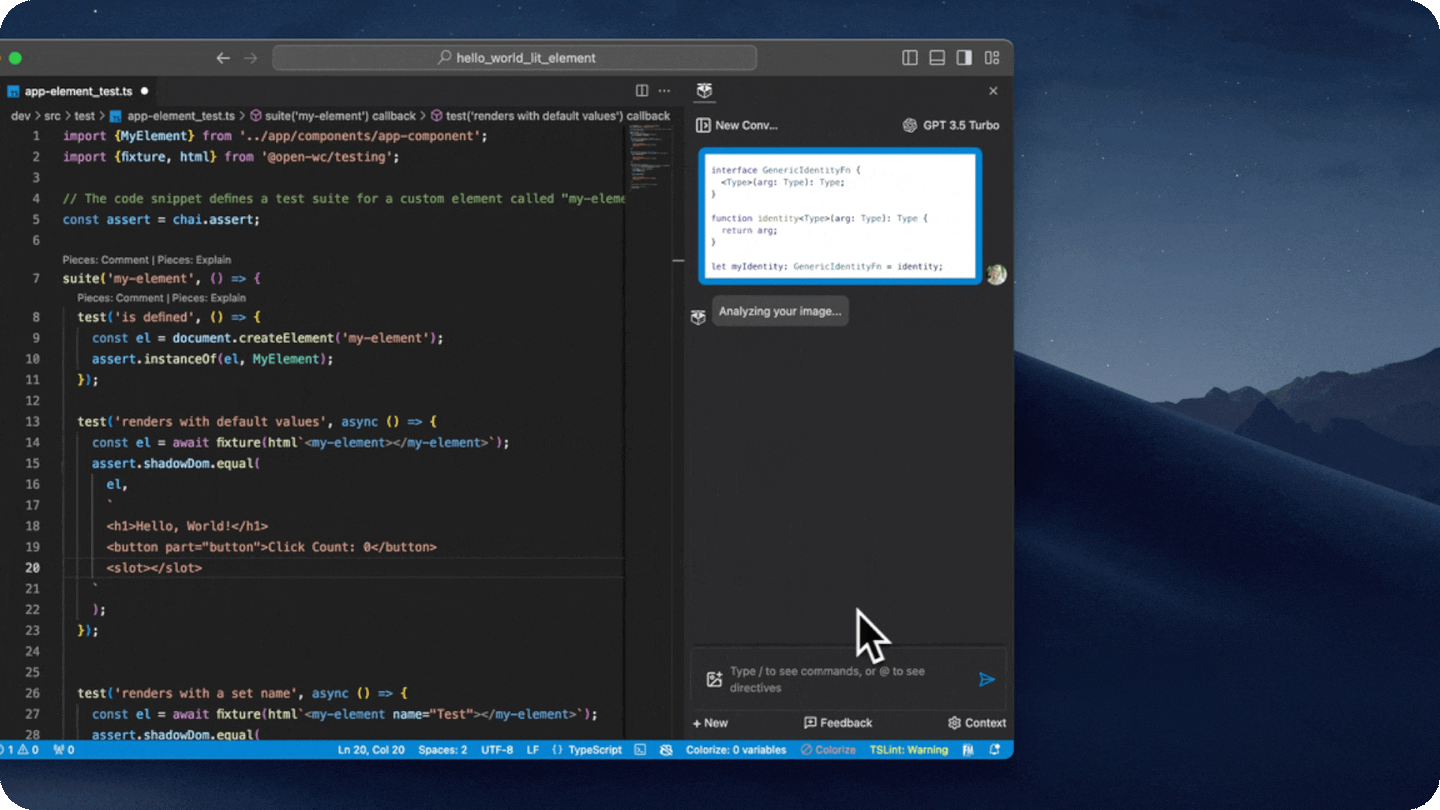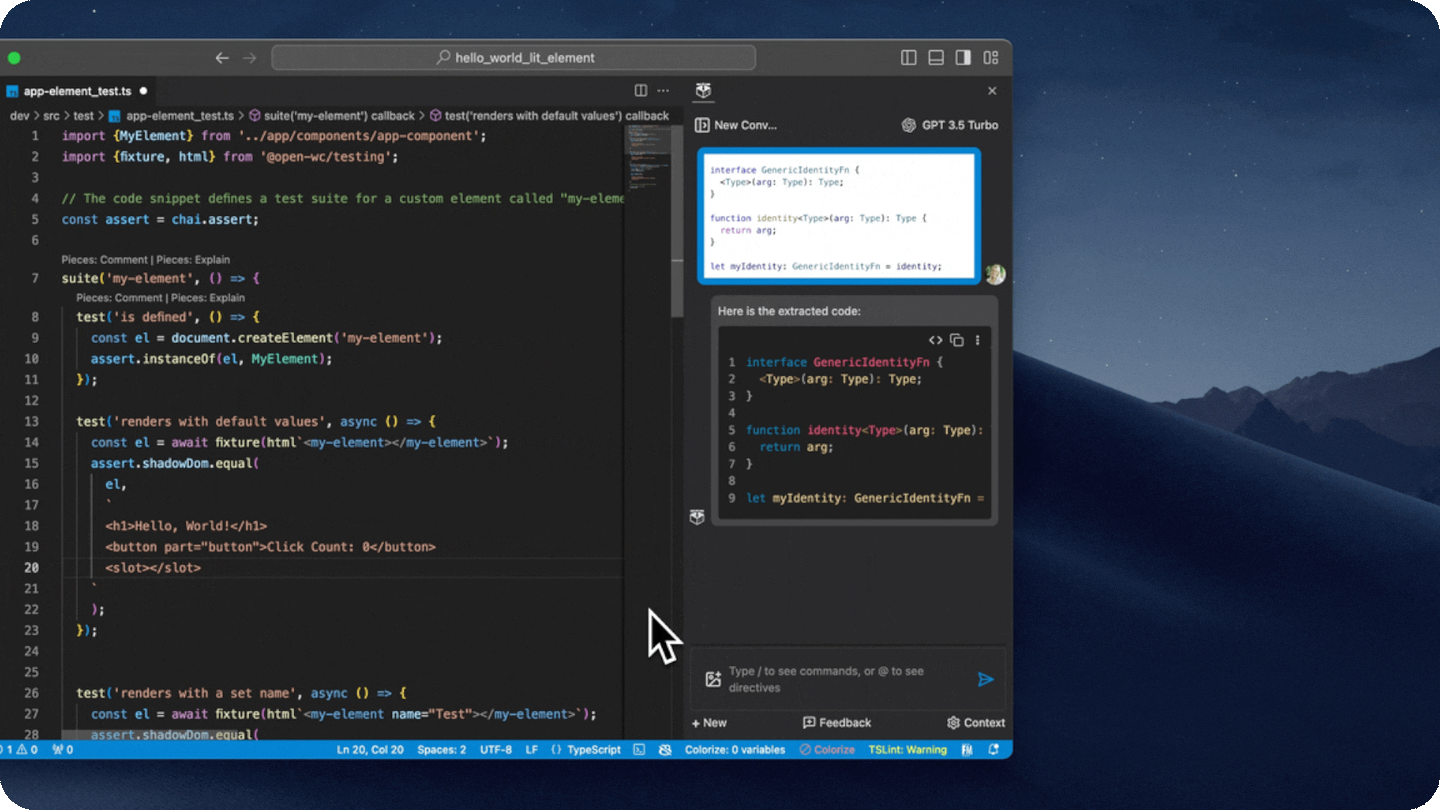
- Extract code from a screenshot either by pasting it into the copilot input, or by clicking on the image icon in the input box.
- Utilize directives to quickly reuse materials as context
- Simply type @ into the input box to see your list of directives or create a custom one.
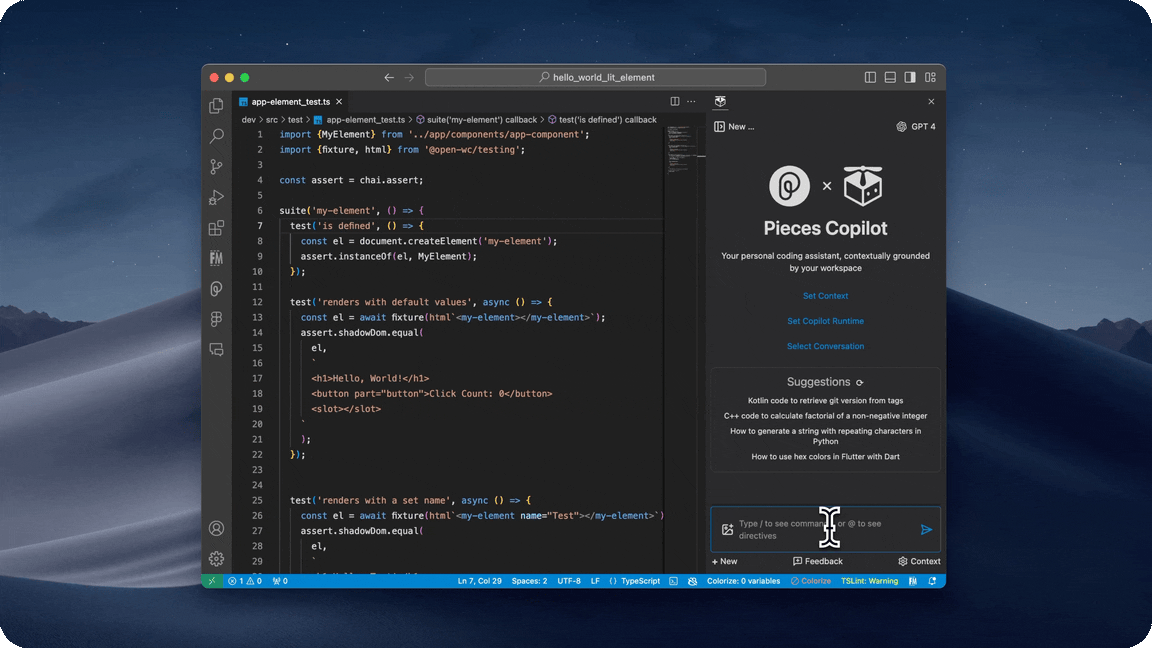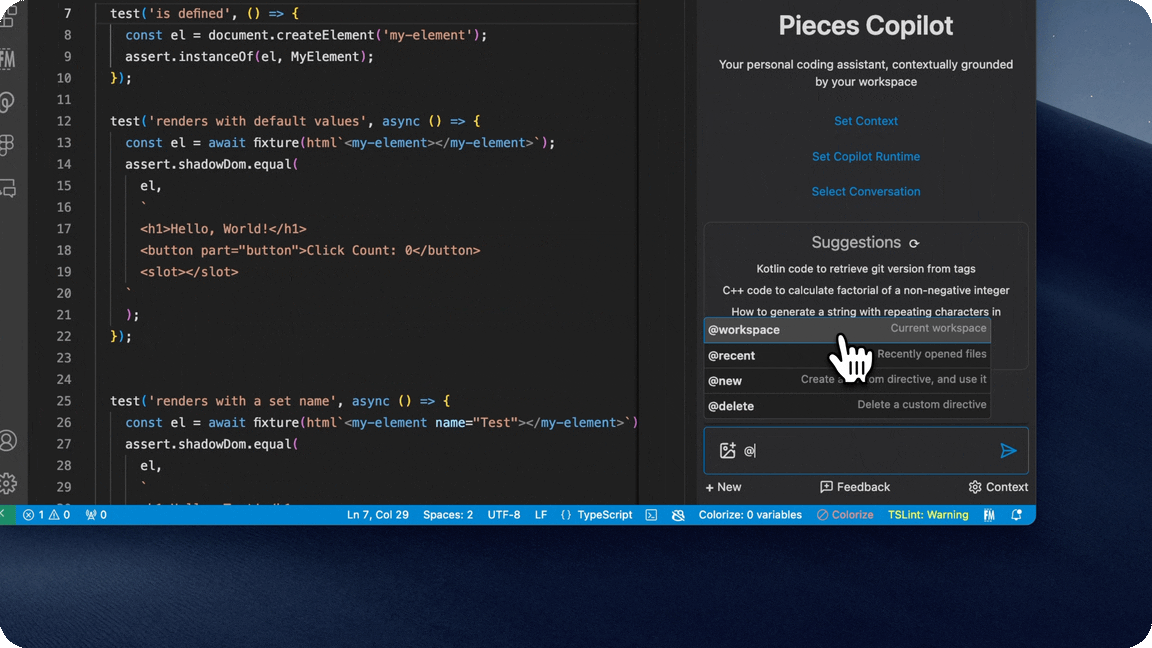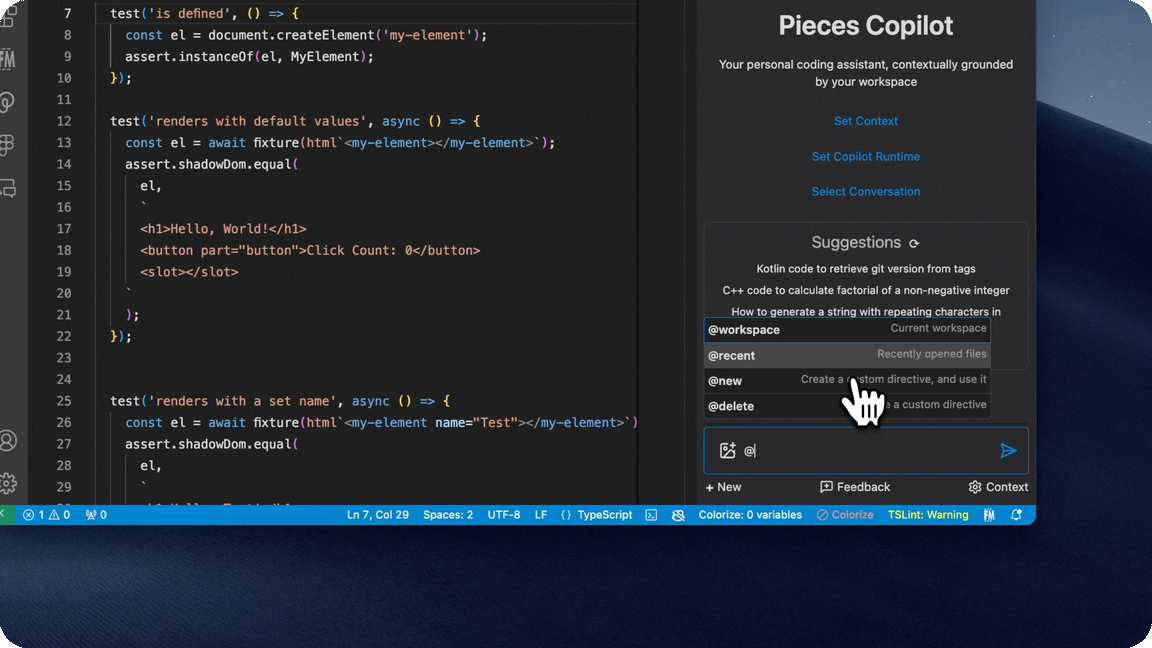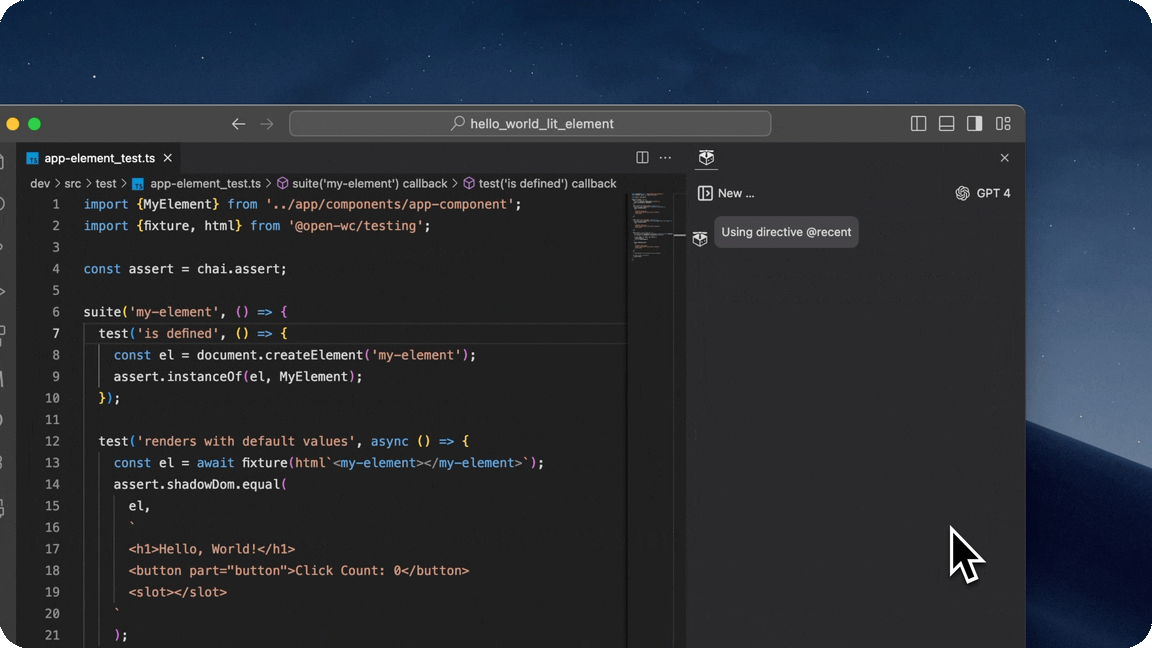
- Simply type @ into the input box to see your list of directives or create a custom one.
- Slash commands to perform quick actions
- Quickly find related people, save snippets, comment code, and more by using a
/command in the input box.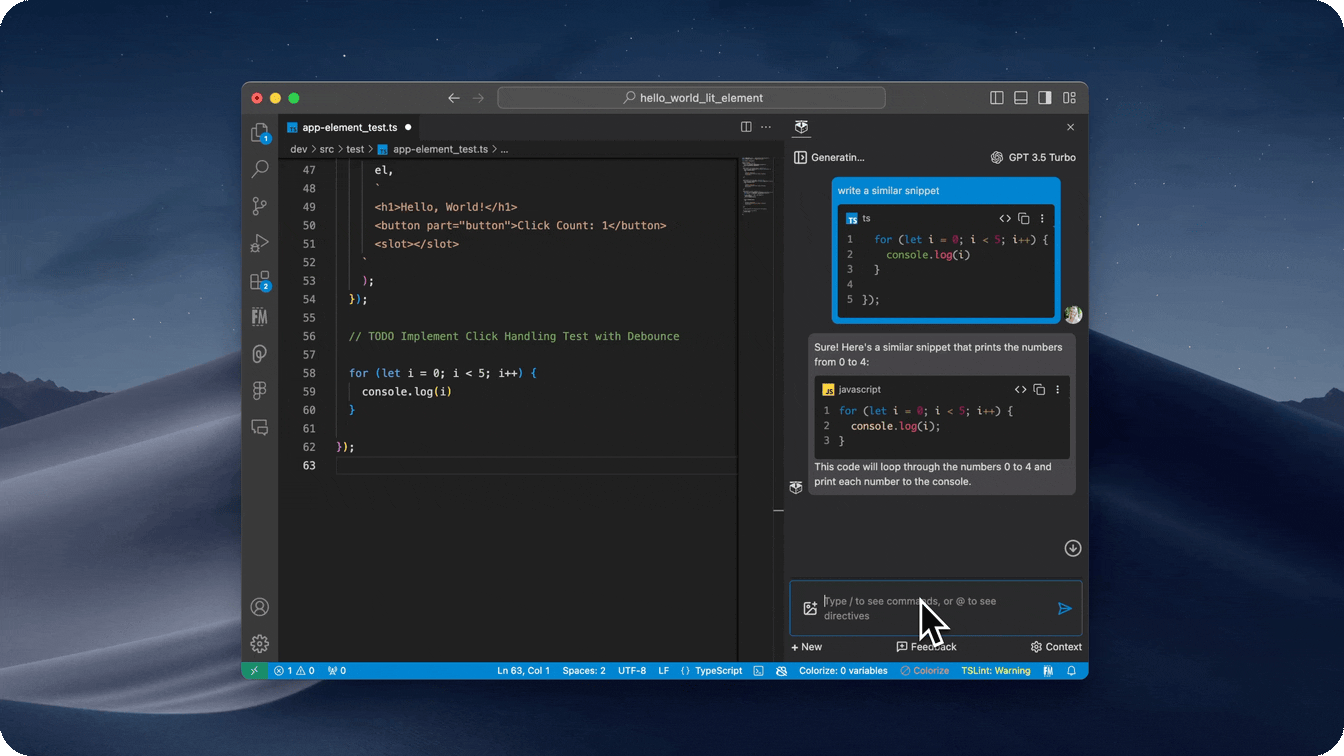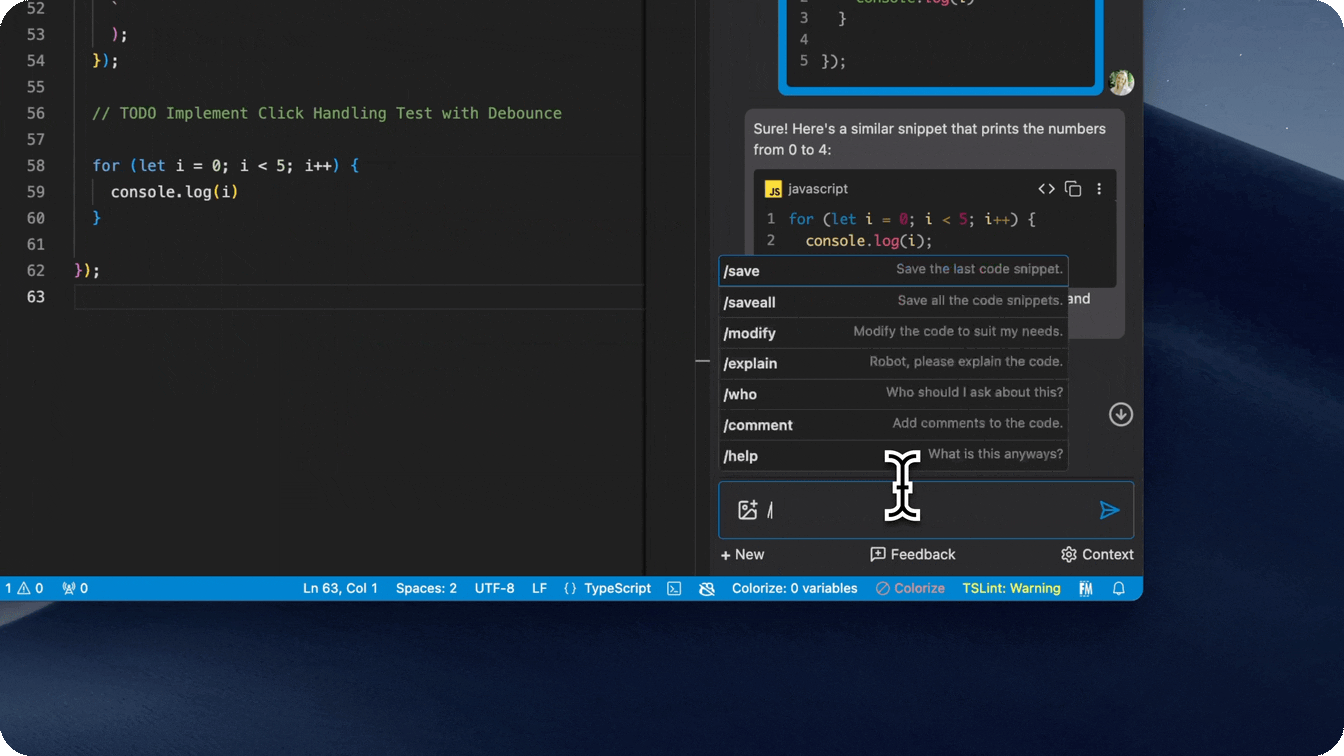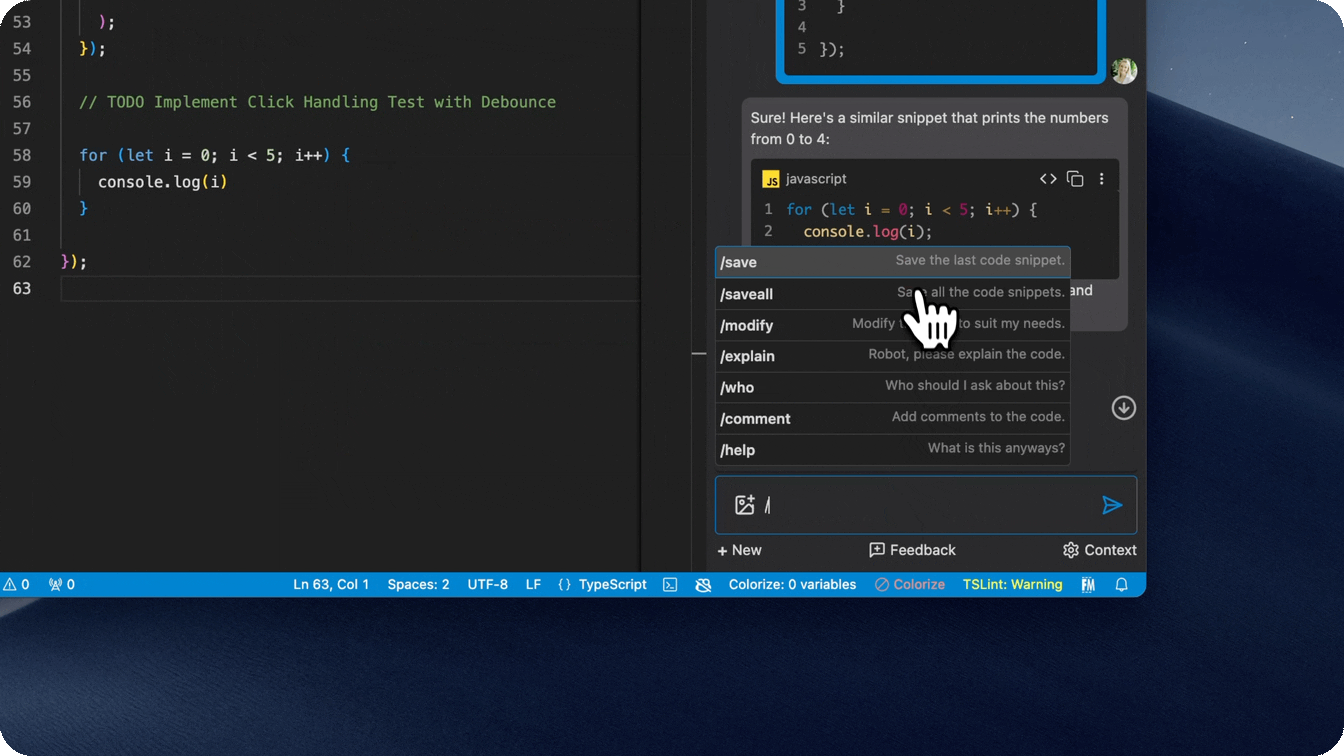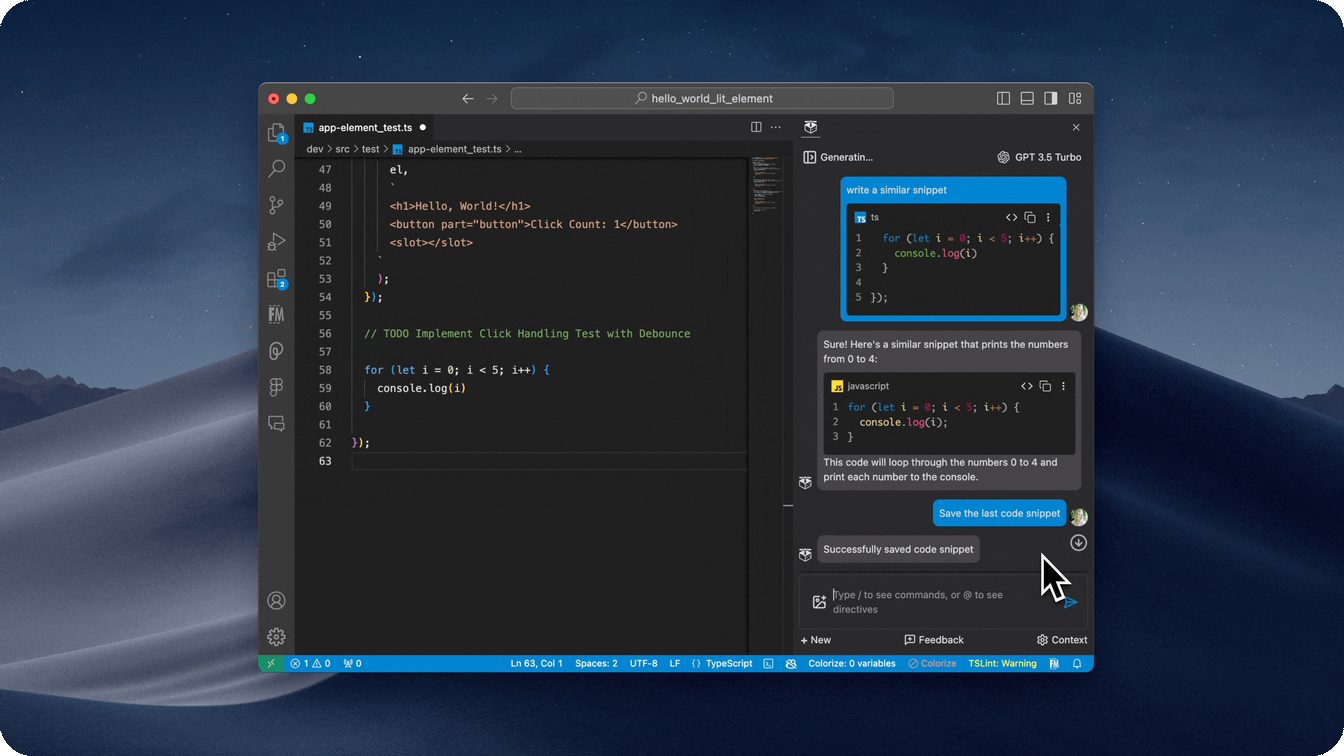
- Quickly find related people, save snippets, comment code, and more by using a
- Go back to your past conversations at any time
- Searchable persistent conversations allow you to go back and see all your past interactions with the copilot, synced across all our integrations.
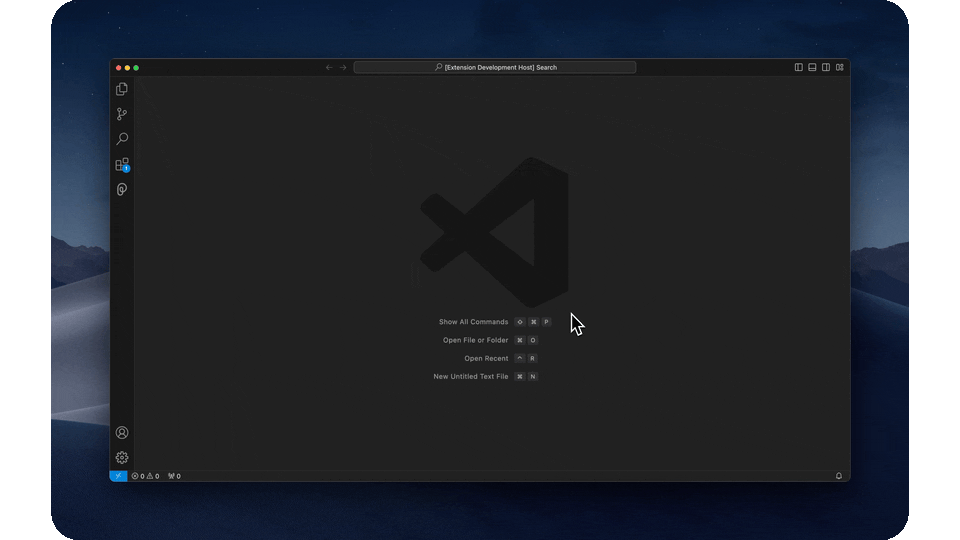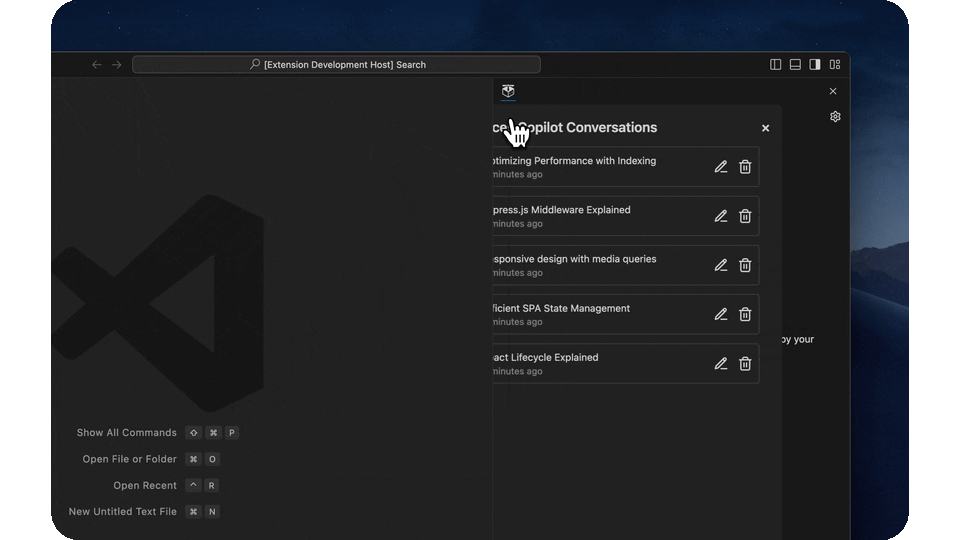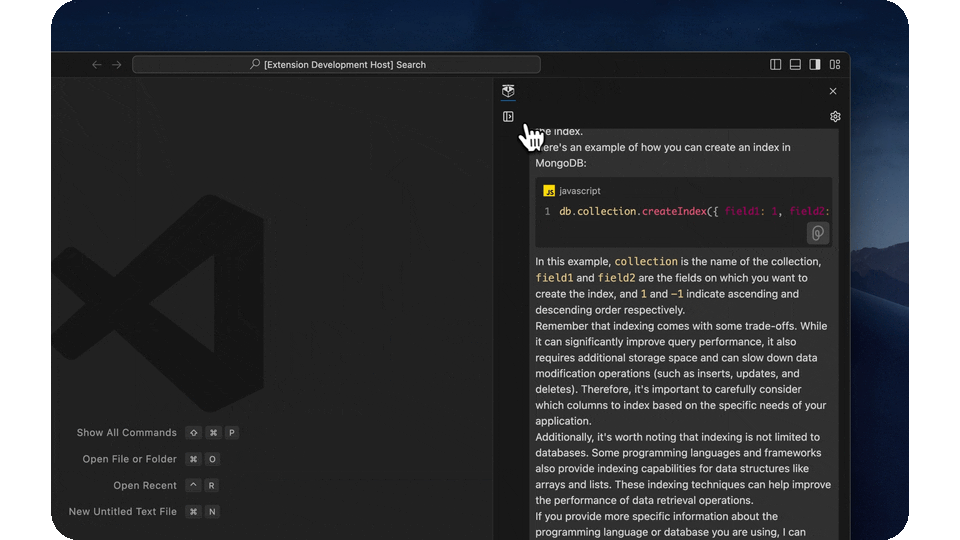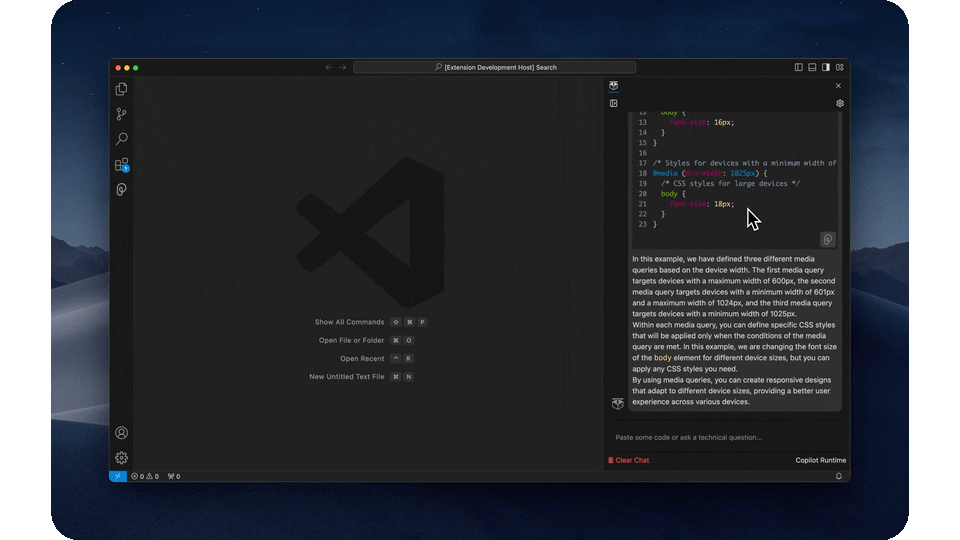
- Searchable persistent conversations allow you to go back and see all your past interactions with the copilot, synced across all our integrations.
- Personalized suggested prompts based on your conversation and saved materials
- We generate suggested prompts for you that are both relevant to what you have saved and what you are chatting with copilot about.
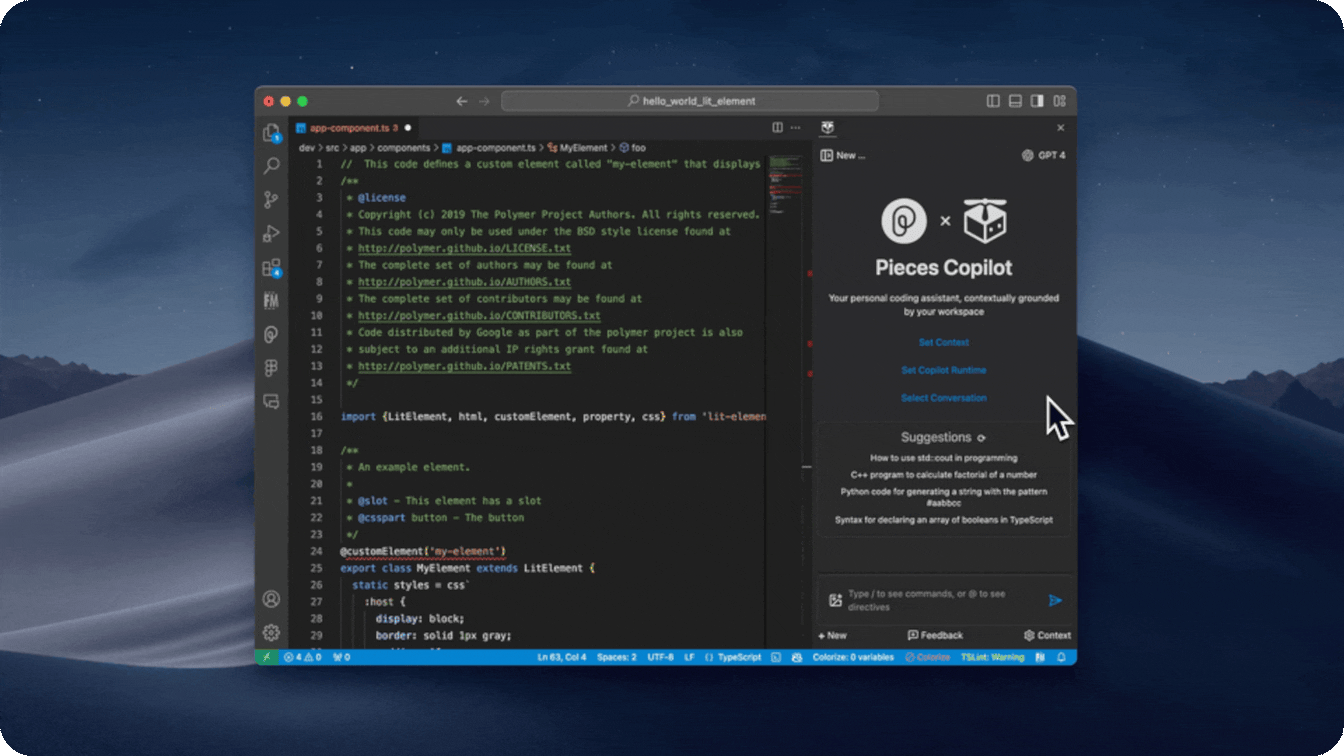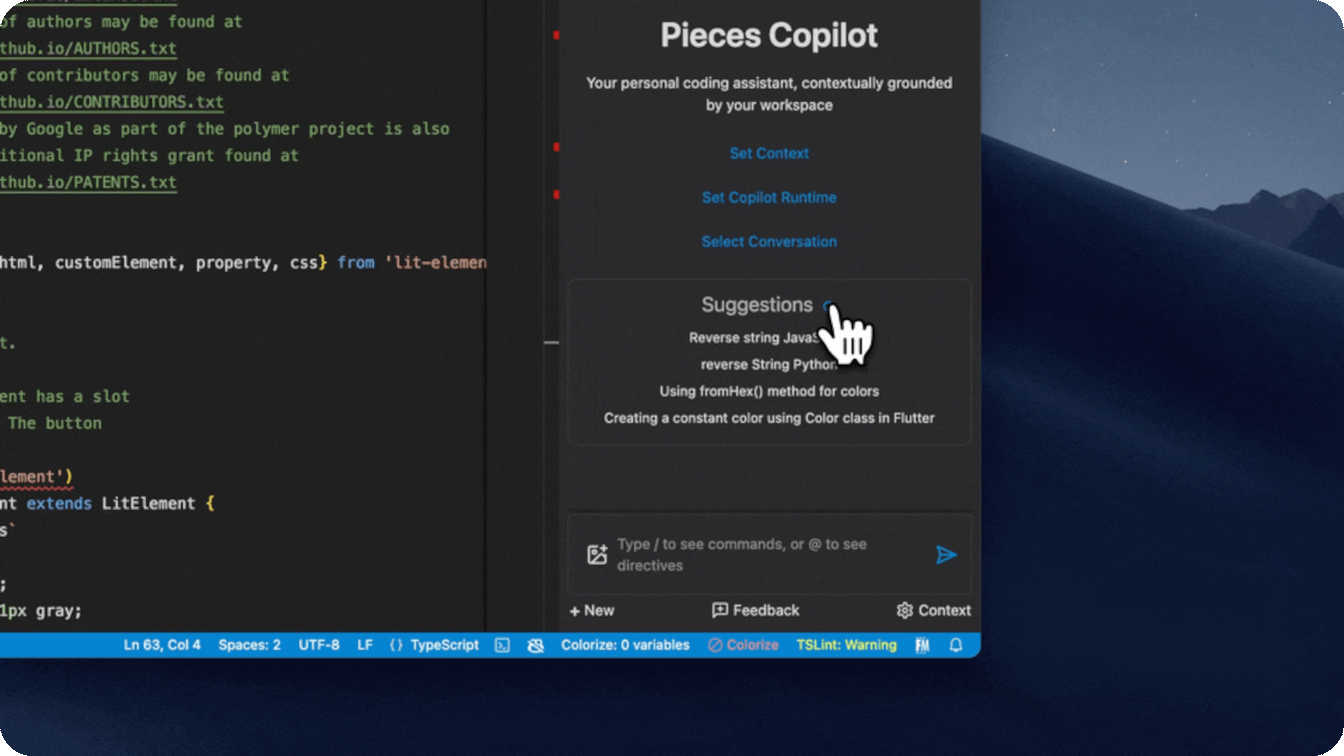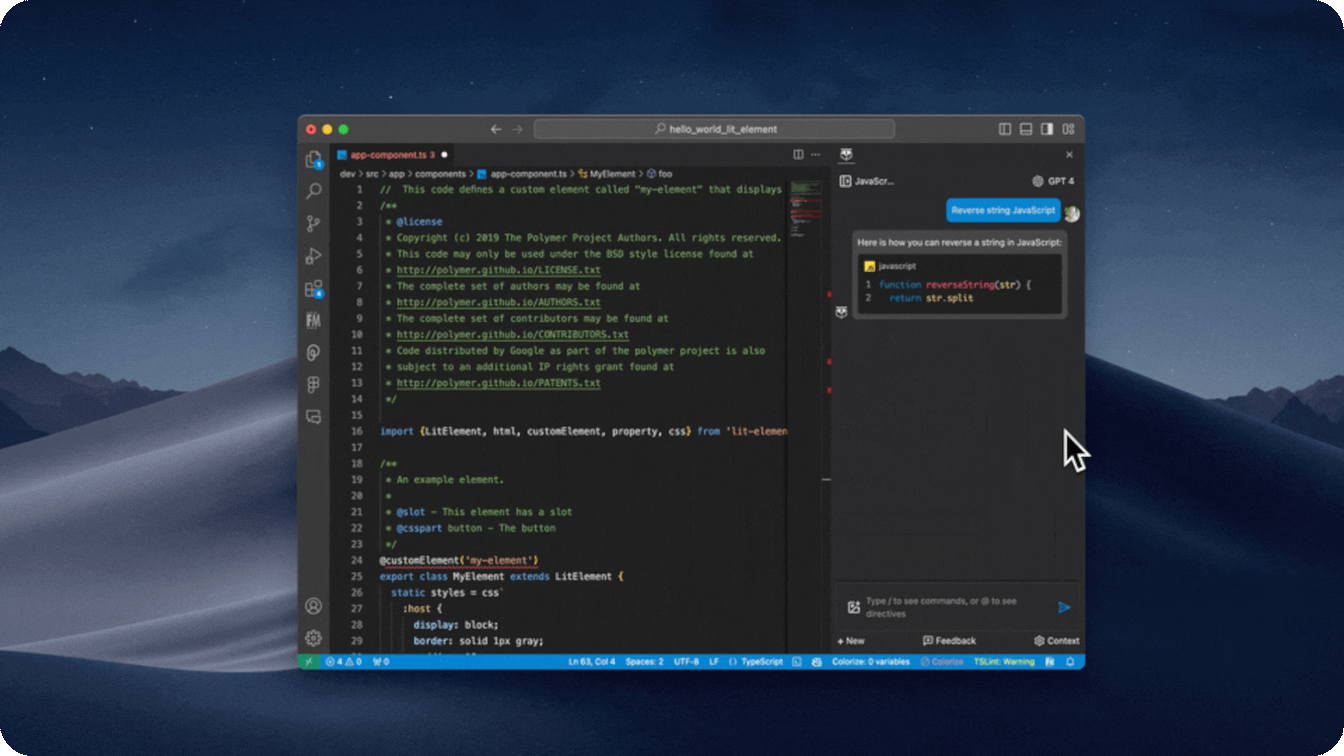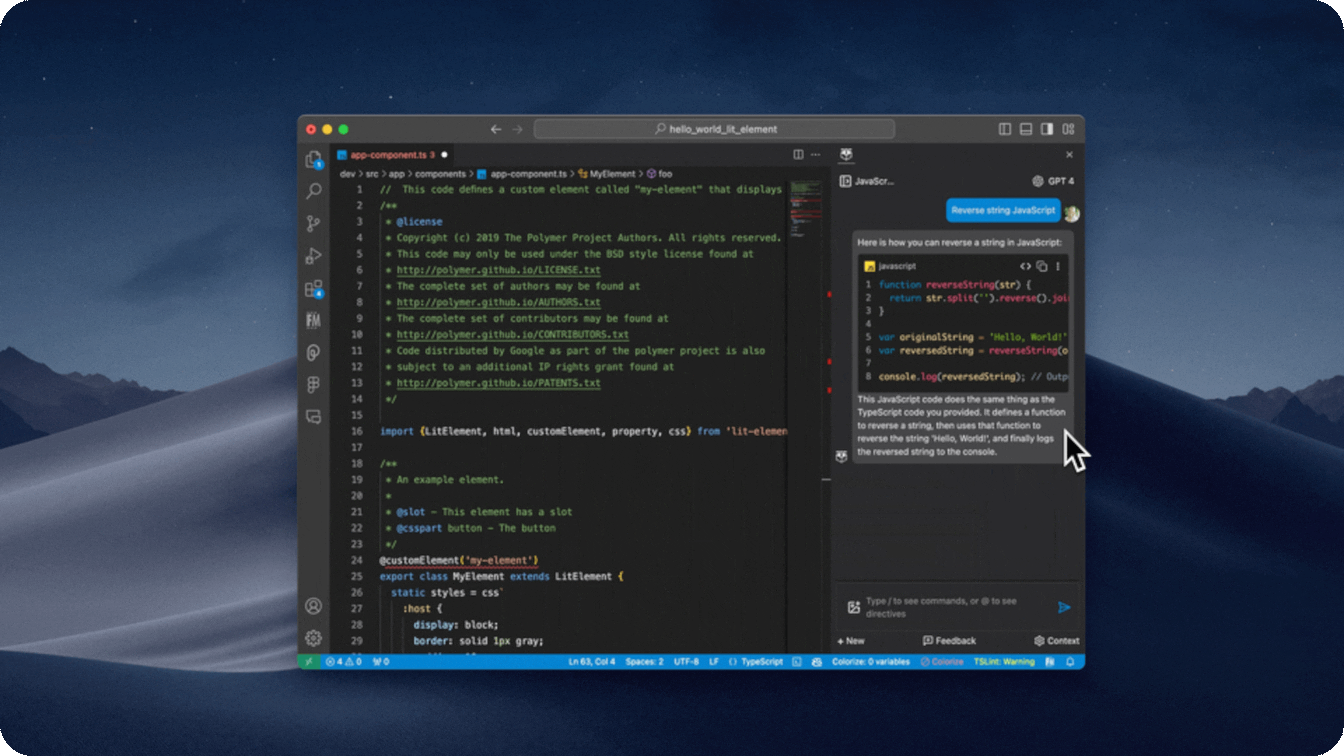
- We generate suggested prompts for you that are both relevant to what you have saved and what you are chatting with copilot about.
- Quickly link back to relevant files
- If the copilot used a file as relevant context, it will show it in the chat window, and you can click on it to view it.
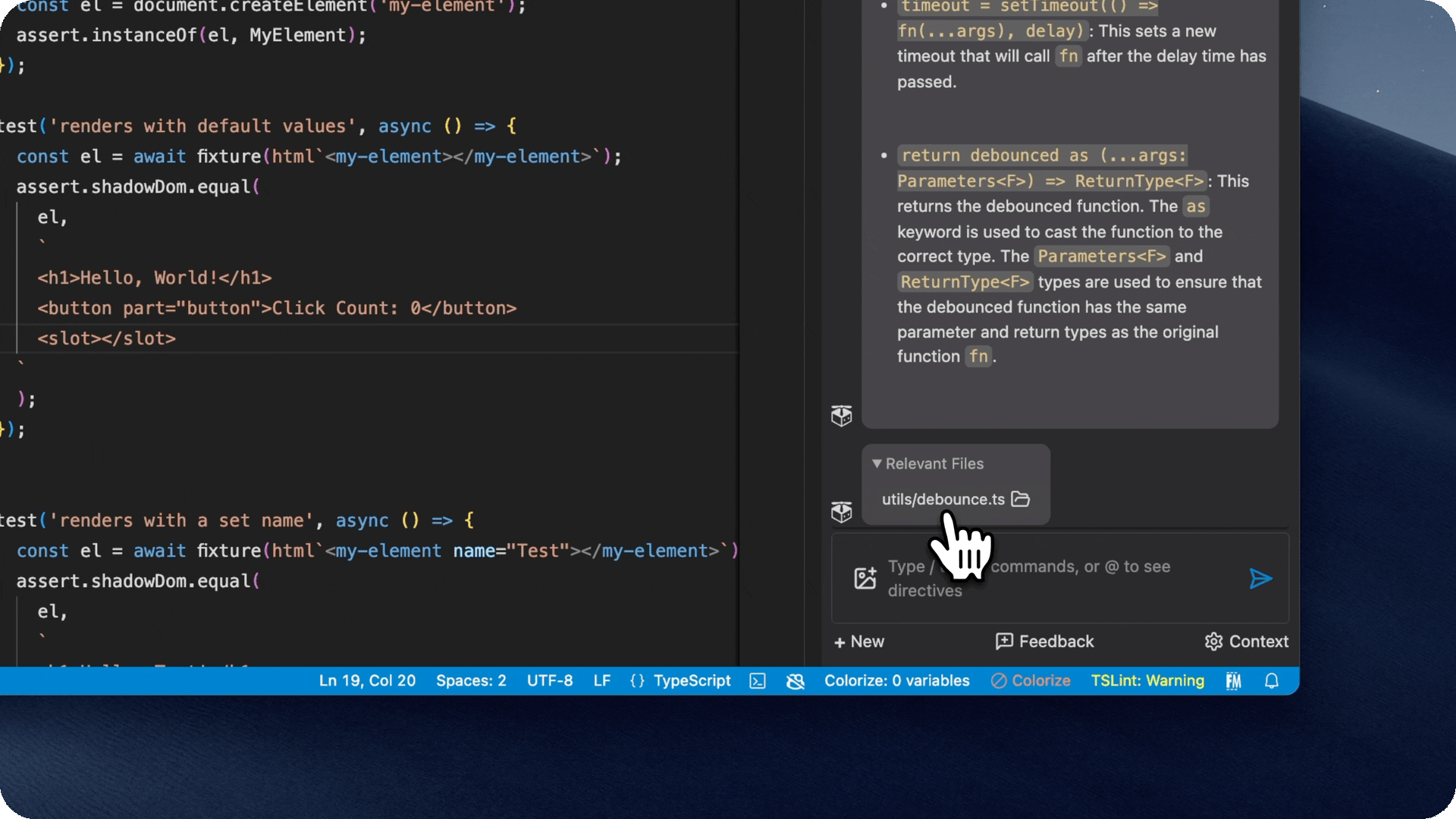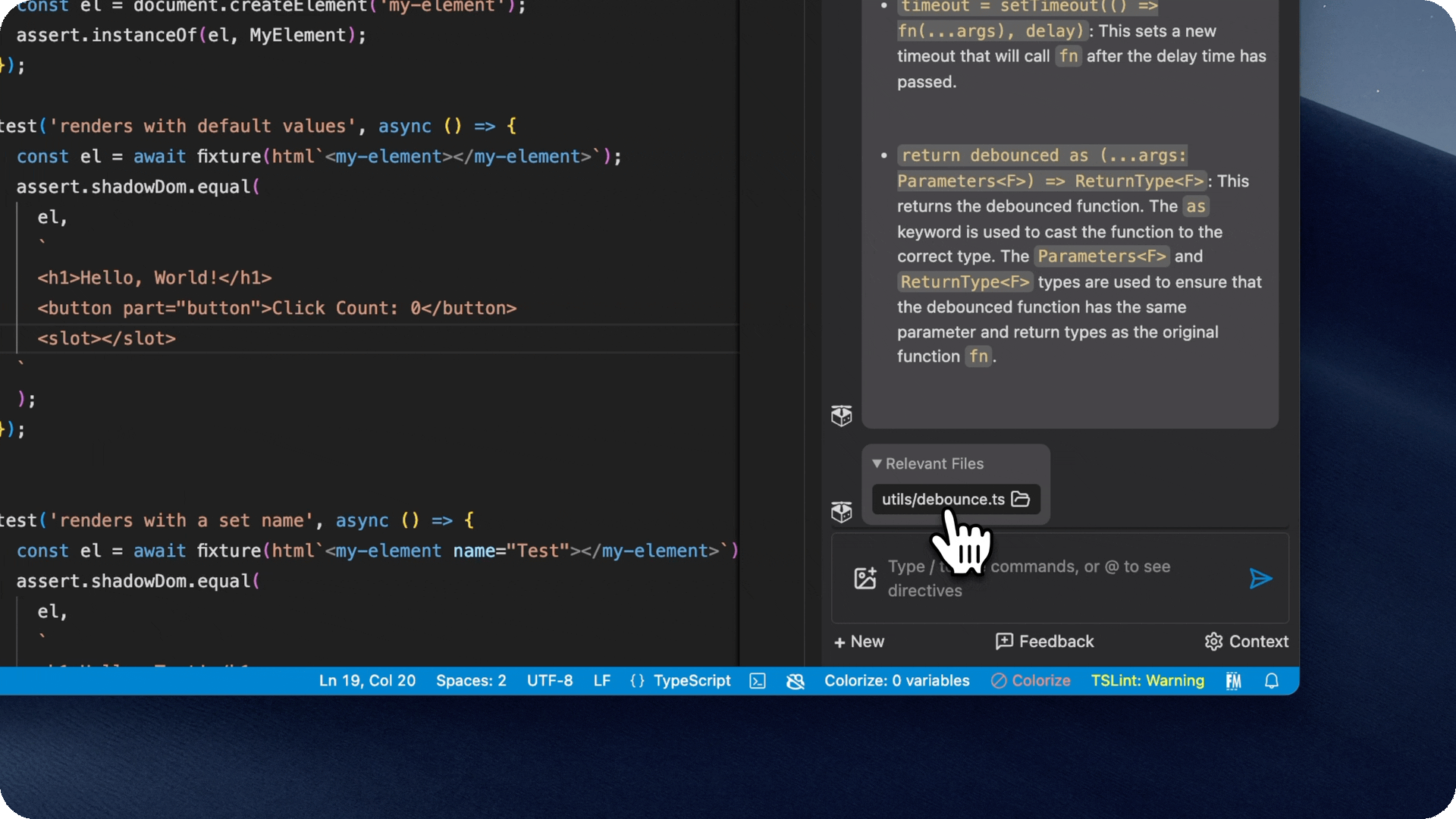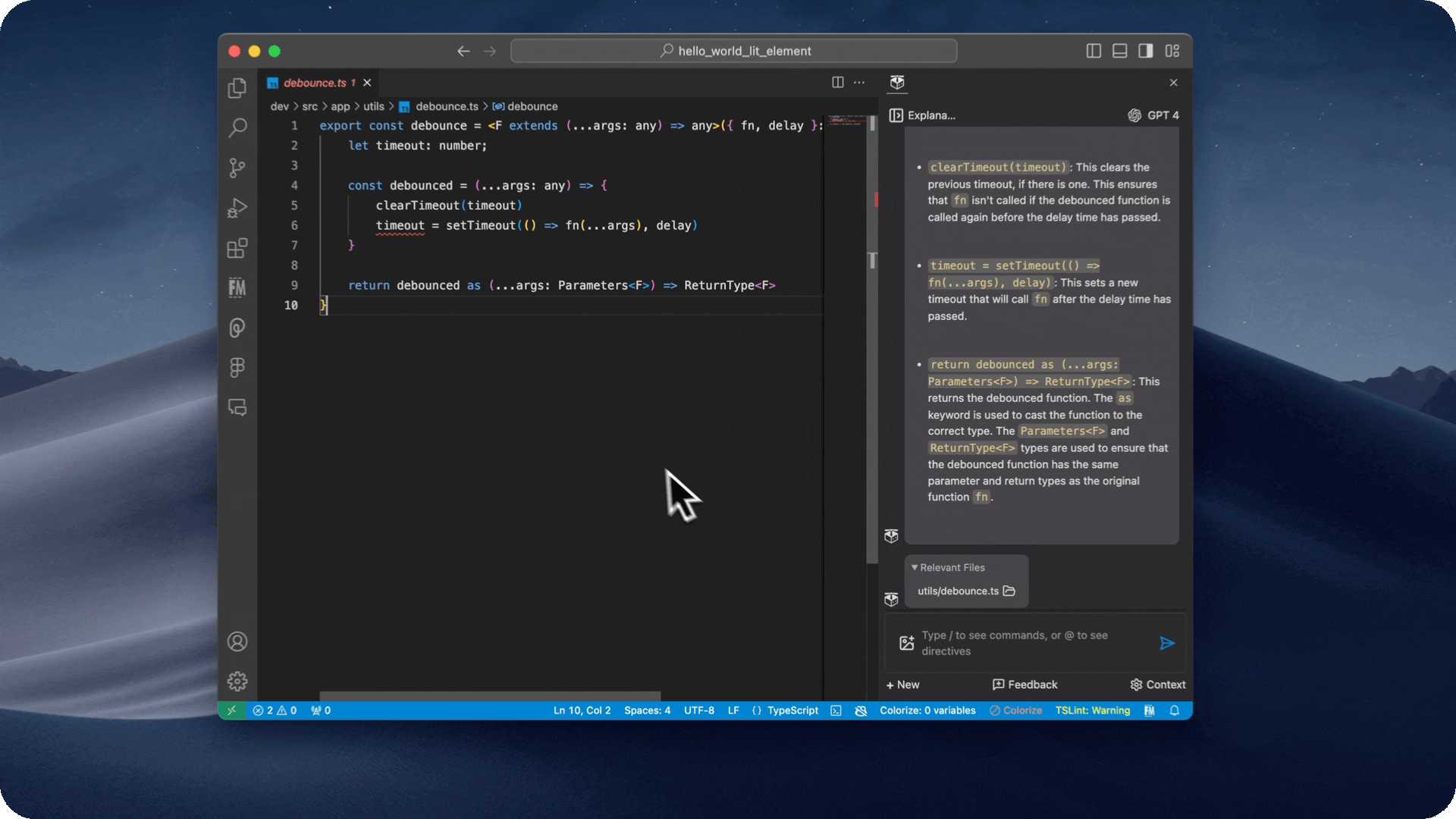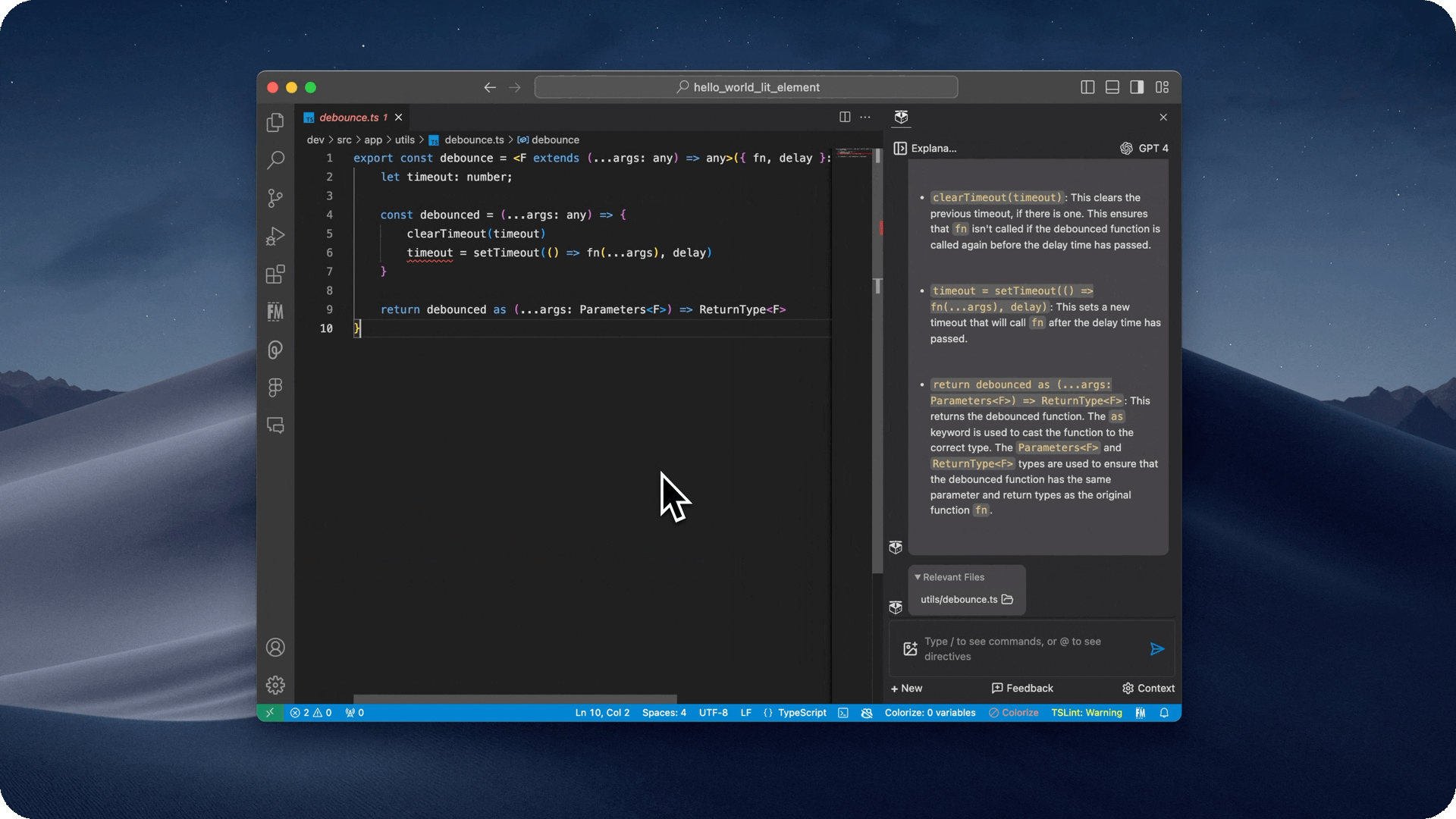
- If the copilot used a file as relevant context, it will show it in the chat window, and you can click on it to view it.
- Support for Latex Formatted Responses
- Any Latex included in generated responses from the copilot will be correctly formatted right in the chat window.
- Theme Customization
- Customize the look and feel of the Copilot chat window to match your preferred theme.
Resetting the Copilot Runtime
If you encounter issues with the Copilot or simply wish to restart your session, there are several methods to reset the active runtime. This can be particularly useful if the Copilot behaves unexpectedly or if you want to clear the current session's context and start fresh.
This can be particularly useful if the Copilot behaves unexpectedly, freezes, or if you want to clear the current session's context and start fresh.
Methods to Reset the Active Runtime
- Double-click the "Stop" Button: Located to the right of the Copilot input box, a quick double-click on the "Stop" button will initiate a reset of the current runtime session.
- Copilot Settings Dialog: Access the Copilot settings by clicking on the settings icon or navigating through the Copilot menu. Within the settings dialog, select "Hard Reset Active Runtime" to restart the session.
- Copilot LLM Runtime Config Dialog: For more detailed runtime configurations, open the LLM Runtime Config dialog. Here, you can select "Hard Reset Active Runtime" to ensure a fresh start for your Copilot session.
Expected Response
After performing any of the above actions, you should receive a confirmation that the active runtime has been reset. This ensures that you are starting from a clean slate, allowing the Copilot to perform optimally in assisting with your coding tasks.
